Using your JupyterLab App
In this article, you will find some guidelines on how to install packages and access workspace files and database tables from your Python and R kernels.
Python kernel
Package management
The Python kernel comes with some of the most common data science packages pre-installed: NumPy, pandas, sklearn, dask, scipy, seaborn, and many more. To see the full list, run pip list in your Python notebook.
To install new packages, you should use pip:
!pip install <package_name>
Accessing files
The JupyterLab working directory is the location of your notebook file. You can print this directory in your notebook using the following command:
import os print(os.getcwd())

In this example, the notebook is saved in the scripts folder in the workspace files.
For example, if you wanted to open a CSV file located in your workspace files as a pandas DataFrame, you would use:
import pandas as pd
data = pd.read_csv('/home/workspace/files/data.csv')
Accessing database tables
The database tables stored in the Database tables tab can be accessed using the psycopg2 package. The module provides functionality for connecting to the PostgreSQL server and performing SQL queries using Python programming language.
To connect to the workspace database:
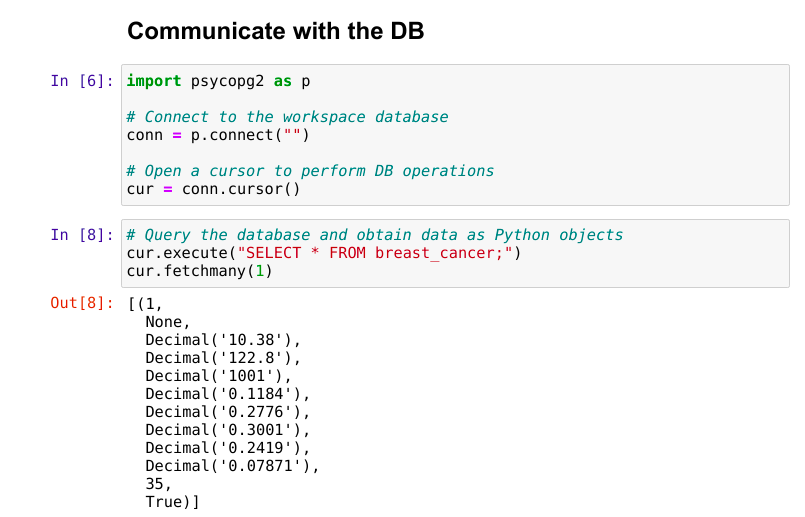
import psycopg2 as p
# Connect to the workspace database
conn = p.connect("")
# Open a cursor to perform DB operations
cur = conn.cursor()
Run your SQL query. This will select all the columns from the breast_cancer dataset, and then will retrieve the first two rows as Python objects:
# Query the database and obtain data as Python objects cur.execute("SELECT * FROM breast_cancer;") cur.fetchmany(2)
Close the communication to the database:
# Close connection
cur.close()
conn.close()
For more information, please see the psycopg2 package documentation.
If you do not want to work with the workspace database directly, you could also try converting your database table to a CSV file first and then reading that file in.
R kernel
Package management
The R kernel comes with a few pre-installed packages such as dplyr, knitr, RPostgreSQL, ggplot2, and ggvis. To see the full list, run installed.packages() in your R notebook.
To install a new package, simply run:
install.packages('package_name')
This will install a package in the /R/version_number/ folder in the workspace files directory. Once a package is installed, it can be loaded anytime, even after if the app has restarted.
Accessing files
The JupyterLab working directory is the location of your notebook file. You can print this directory in your notebook using getwd() command.

For example, if you wanted to import data from a CSV file located in your workspace files into a data frame, you would use:
data <- read.csv('/home/workspace/files/data.csv')
Documentation
For further user guides and documentation, see JupyterLab's own website here (opens a new tab)