Duplicating Dataset Metadata
As an alternative to creating a completely new dataset, a data owner can choose to duplicate the metadata of an existing dataset that they own. Data owners cannot duplicate the metadata of datasets they do not own.
The option to Duplicate the metadata of a dataset is available from the elipses on the right of the Browse tab...
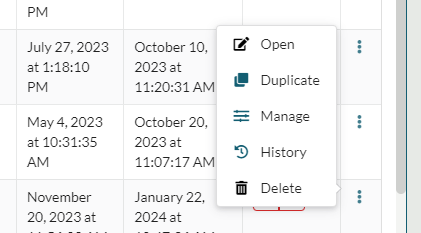
... and is one of the actions on the Dataset tab:
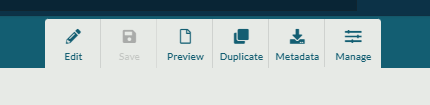
When a user selects the Duplicate option, it opens a new dataset tab in edit mode.
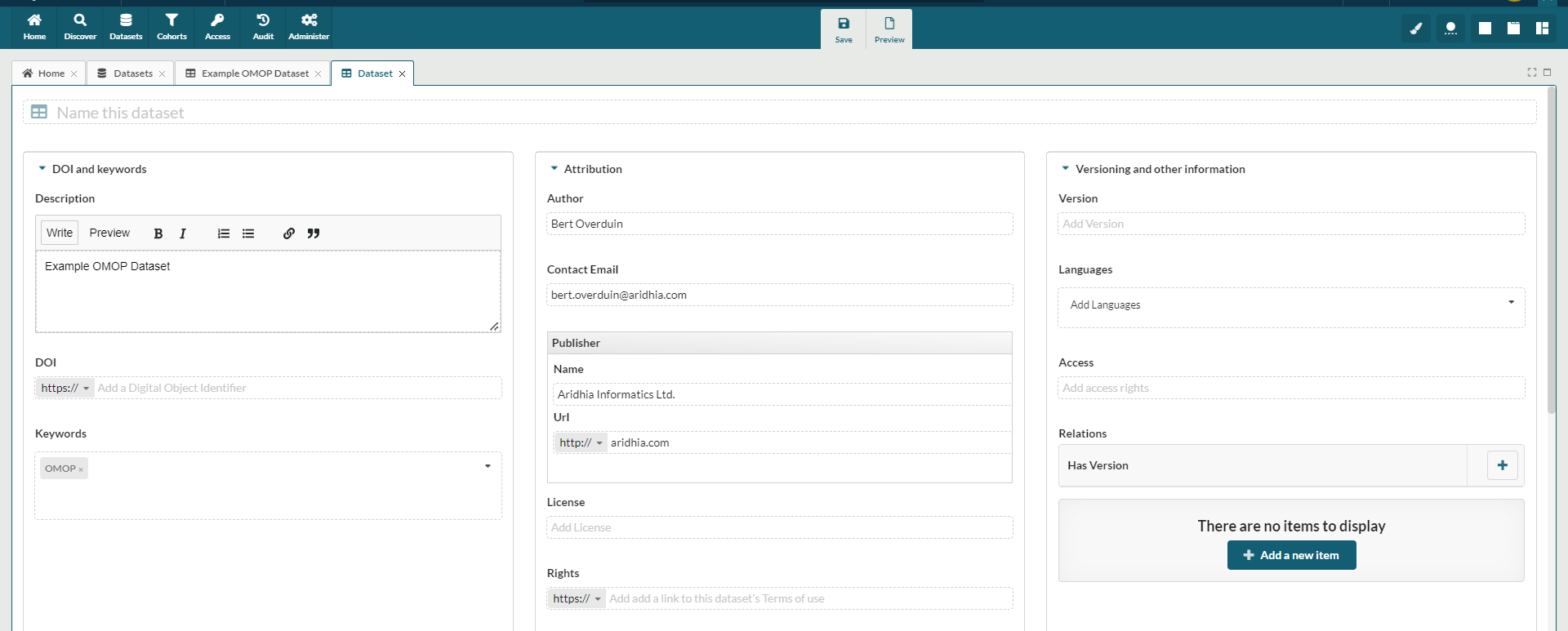
All of the catalogue metadata of the parent dataset will be maintained, but the user needs to give the dataset a new name before saving. The visibility of all datasets created this way will be set to private by default.
A full list of all the metadata and settings and if these are retained by a duplicate is provided
below:
| Item | Type | Duplicated | Notes |
|---|---|---|---|
| Catalogue | Metadata | Yes | All existing catalogue values are duplicated, but a new name must be selected |
| Dictionaries | Metadata | Yes | All dictionaries and dictonary fields are duplicated |
| Lookups | Metadata | Yes | |
| Cohort selection | Dataset setting | Yes | |
| Subscriptions and notifications | Dataset setting | Yes | The subscription settings are duplicated, but the duplicate dataset has no subscribers |
| Data access requests | Dataset setting | Yes | |
| Visibility | Dataset setting | No | All duplicates are set to private by default |
| Name | Metadata | No | The user needs to name the duplicate before saving |
| Dataset and dictionary codes | Metadata | No | FAIR will create new codes for the duplicate |
| Attachments | Resource | No | Attached files are not duplicated, this includes data files |
| Collections | NA | No | |
| Users | NA | No | The creator of the duplicate dataset is the only user at the point of creation |
Underlying data is not duplicated as part of this process.