Shared Compute Resources in Workspaces
There are certain tools and apps within a workspace that run on compute resources that are shared across the entire hub. They are the Apps (like the Built-in Apps R Development Environment and Jupyter Notebooks), Web Apps, Data Table Analytics modules, and the R console.
The use of scalable compute reduces the need for Virtual Machines within a workspace which in turn can lower costs across the entire hub.
How the setup works
A node runs on a Virtual Machine that’s always available and attached to the hub and all nodes are hosted on Azure Kubernetes (AKS). The tools and apps run in containers, and they can be defined as isolated execution environments. Kubernetes is a service that coordinates and manages those containers on Azure computing resources. The Virtual Machine that makes up the node can be set to different sizes depending on the user's needs. The bigger the Virtual Machine, the higher the cost will be to run it. The standard size of a node is 8 cores and 16 GB RAM and is made up by a Microsoft Azure Standard_F8s_v2 Virtual Machine.
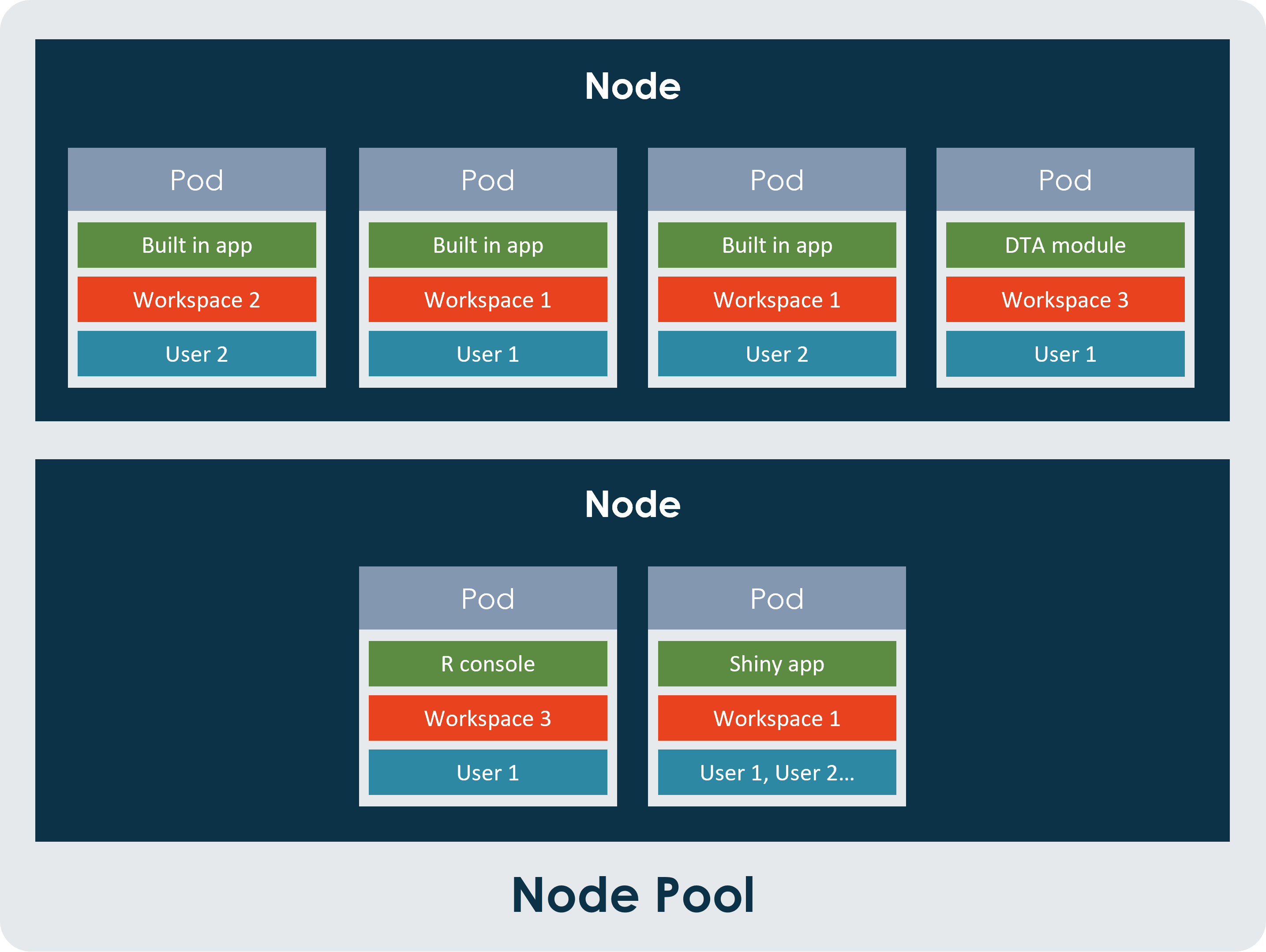
Pods on the nodes
When you start one of the tools or one of the apps, a pod is created on the node and allocated a slice of the compute resources from the Virtual Machine that hosts the node. The standard guaranteed size of a pod is 0.75 CPU core and 1 GB RAM and it can automatically grow to a maximum size of 1.5 CPU cores and 10 GB RAM based on need and provided there are enough resources left on the node. Both the guaranteed size and the maximum size of the pod can be set per tool. To request a change to the sizes of the pods, please contact our Service Desk for assistance.
Node pool and limits
When another user starts a tool, a new pod is added to the node and compute resources are allocated to that pod. When all the resources on the node have been allocated, a new node is created, i.e. a new Virtual Machine is spun up, and any new pods that needs to be created will be created on the new node. As standard, the maximum number of nodes in a node pool is 10. This limit is in place to make sure that the cost of running the service doesn’t become too high, but it can be increased by special request.
The different tools
Each tool behaves slightly differently depending on how it is set up.
For Web apps: A tool from one workspace gets one pod that all users within that workspace connect to. Only one Pod is created for this app per workspace. This means that if one user starts the app, they get one pod to run that app in. If another user also starts that app within the same workspace, the second user will be connected to the same pod as the first user.
For Apps, Data Table Analytics modules, and R Console: Each user within a workspace, for each tool they start, gets their own pod on the node. If another user starts the same tool in the same workspace, they will run that tool in a new pod.
Example diagram: