What is a Dataset?
Definition
A FAIR dataset describes and provides metadata on a set of tabular data and consists of the following entities:
- A single catalogue entry describing the dataset that is compliant with the W3C DCAT standard.
- Zero or more dictionary entries describing the dataset at the field-level.
- Zero or more controlled vocabularies per dictionary.
- Zero or more attachments that will enhance the metadata of the dataset such as PDFs, JSON, etc.
- An optional Data Access Request (DAR) workflow (for DAR-enabled customers only) A dataset in FAIR Data Services is therefore defined as a single entry in the FAIR service aligned to a single dataset catalogue, i.e. a dataset is equivalent to one dataset catalogue including its attachments and associated data dictionaries.
Dataset Display
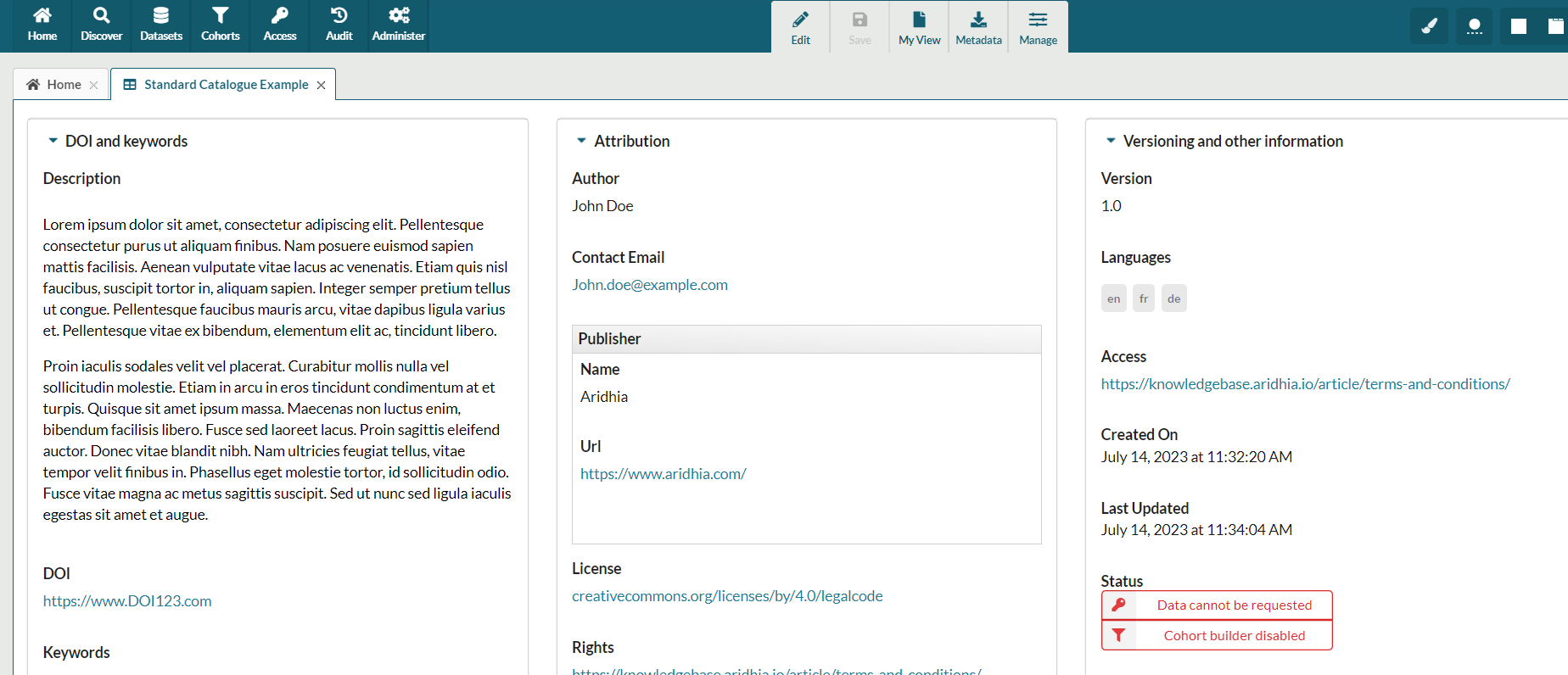
Below is an example of how a dataset is displayed in FAIR.
Catalogue
Catalogue information is displayed at the top with dataset title, the default catalogue contains the following sections and associated fields:
DOI and keywords
- Description
- DOI
- Keywords
Attribution
- Author
- Contact email
- Publisher
- Name
- URL
- License
- Rights
Versioning and other information
- Version
- Language
- Access
- Relations
Created On and Last Updated data is automatically generated by the service, and the request and cohort statuses are set from the Dataset Administration Tab.
A machine-readable version (JSON) of the catalogue can be downloaded by selecting ‘Download' then ‘Catalogue’ from the actions ribbon. Similarly, a machine-readable version of the entire dataset can be downloaded by selecting ‘Download’ then ‘All Metadata’ in the actions ribbon.
FAIR also allows users to create their own custom catalogue. The data owner can choose to apply one of these to their dataset from the Dataset Administration tab:
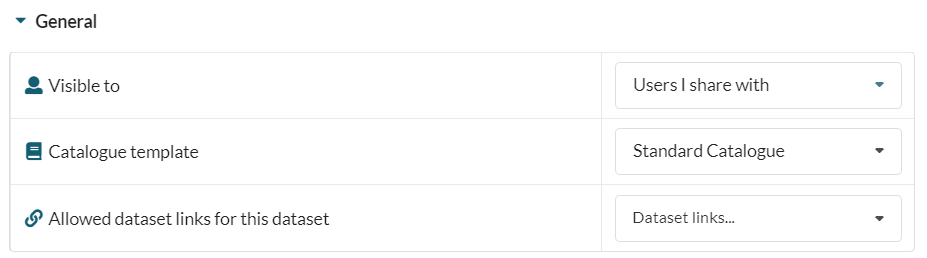
For more information on creating custom catalogue templates see the Custom Catalogues article in the Administering FAIR section.
Dictionary
Dictionary information where datasets with multiple dictionaries (e.g. multiple tables in a database) can be navigated between using the inline dictionary dropdown menu.
Dictionaries contain the following fields:
- field name (mandatory)
- field label (mandatory)
- field type (optional)
- description of the field (optional)
- URI for field (optional)
- PMN rule for field (applicable if PMN service enabled)
- Entity flag (identifies field values as unique if on)
- Cohort filter for field (applicable if cohorts enabled)
A machine-readable version (JSON) of the dictionary can be downloaded by selecting ‘Download' then ‘Dictionary’ from the actions ribbon. Similarly, a machine-readable version of the entire dataset can be downloaded by selecting ‘Download’ then ‘All Metadata’ in the actions ribbon.
Controlled Vocabulary
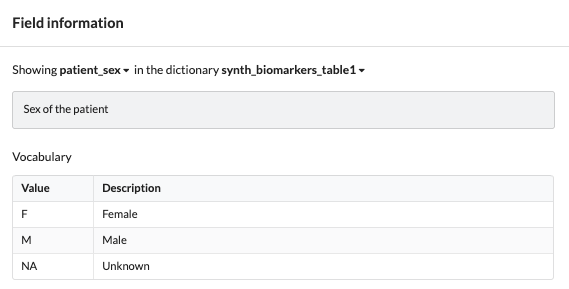
A controlled vocabulary can be set and viewed per field outlining the restrictions of values a particular field can take. For example, a ‘patient_sex’ field may only take the values of ‘M', ‘F’ or 'NA’ describing male, female or unknown sex patients.
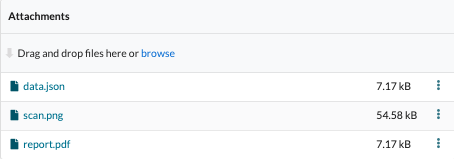
Attachments
Attachments can be added to the dataset, via a drag-and-drop or dialog interface, to enhance the quantity and quality of metadata.